来锐捷实习了,我每天的任务是写两个脚本,但奈何我。。。
又不想虚度光阴,认真看看好了。
这里伙食确实不错。
R-CNN 系列
R-CNN:Rich feature hierarchies for accurate object detection and semantic segmentation (CVPR 2014)
背景:首次用深度学习CNN的方式进行目标检测的尝试。之前都是使用传统提取特征,比较好的是SIFT和HOG。【看代码复习】
创新点:
使用候选区域,与滑动窗口方法相比,CNN处理的图像窗口减少了两个数量级。
CNN提取特征:RCNN使用的CNN网络是AlexNet。
有监督pre-training+domain-specific finetuning处理label少的情况
使用bounding box regression进行修正【?具体】
目标检测:
生成候选区域:
选择性搜索【一张图像生成约2K个候选区域 (Selective Search)】目的是为了改善传统提取特征方法中机从左到右、从上到下枚举式的低效。
Selective Search:过分割,将图像分成小区域;合并可能性最高的相邻两个区域
http://koen.me/research/pub/uijlings-ijcv2013-draft.pdf
【相关论文 颜色、纹理相近;尺度要均匀:不能大鱼吃小鱼;形状】;输出所有候选区域。
基于上述方法搜出的候选框是矩形的,而且是大小各不相同。为了要得到固定尺寸的图片输入到CNN中,进行缩放。作者比较了两种方法:1 各向异性缩放:不管比例 直接缩到227*227 ;2 各项同性缩放:将边界拓展成正方形 然后不在框里面的直接用框外的颜色均值代替填充;用固定背景颜色填充
本文:采用各向异性缩放、padding=16的精度最高
如果用selective search挑选出来的候选框与物体的人工标注矩形框的重叠区域IoU大于0.5就把这个候选框标注成物体类别,否则就是背景。
特征提取:
对每个候选区域,使用深度卷积网络提取特征 (CNN)
比较:VGG和AlexNet。前者精度高但是计算量是后者的7倍。
物体检测的一个难点:物体标签训练数据少,若直接采用随机初始化CNN参数的方法,训练数据量是不够——采用的是有监督的预训练。
AlexNet原本是做图像分类任务,为做目标检测任务,替换掉AlexNet的最后一层的全连接层(4096 * 1000)。
1pre-train:采用了迁移学习的思想: ImageNet训练的CNN,先进行网络图片分类训练。该数据库有大量的标注数据,共包含了1000种类别物体,预训练阶段CNN模型的output 1000个神经元。
网络优化:采用随机梯度下降法,学习速率大小为0.001
2fine-tune:在小型目标数据集(PASAC VOC)对上面得到的model进行改动。将模型的最后一层修改类别数。(20+1background)
RCNN的结构实际是5个卷积层、2个全连接层。
input: 2000 227 * 227 * 3
output: 2000 * 4096 * 1
从每个候选区域中提取4096维特征向量。特征是通过前向传播通过五个卷积层和两个全连接层减去平均的224X224 RGB图像来计算的
线性SVM分类器:
训练过的对应类别的SVM给特征向量中的每个类进行打分,每个类别对应一个二分类SVM。output: 2000*N(N目标的类别)作者测试了IOU阈值各种方案数值,通过训练发现,IOU阈值为0.3效果最好。IoU>0.3的region proposal的特征向量作为正例,其余作为负例。
减少bbox:非极大值抑制法
测试时:2000×4096维特征与N个SVM组成的权值矩阵4096×N相乘,每一列即每一类进行非极大值抑制剔除重叠建议框
【CNN做特征提取(提取fc7层数据),再把提取的特征用于训练svm分类器原因:CNN容易过拟合,需要大量训练数据,因此CNN训练数据做了比较宽松的标注,一个bounding box正样本可能只包含物体的一部分,用于训练CNN。SVM适用于少样本训练,对于训练样本数据的IOU要求比较严格,只有当bounding box把整个物体都包含进去了,才把它标注为物体类别】
Bounding Box 回归:
就是得到的候选框可能与ground truth相差比较大。解决:利用回归的方法重新预测了一个新的矩形框,借此来进一步修正bounding box的大小和位置
边界框回归是利用平移变换和尺度变换来实现映射。
使用相对坐标差:【比例值是恒定不变的;对坐标偏移量除以宽高即做尺度归一化:尺寸较大的目标框的坐标偏移量较大,尺寸较小的目标框的坐标偏移量较小】
IoU大于0.6时,边界框回归可视为线性变换:【log(1+x)/x x趋近0 整个趋近于1】
AlexNet第5个池化层得到的特征即将送入全连接层的输入特征的线型函数。
存在问题:R-CNN需要两次进行跑CNN model,第一次得到classification的结果,第二次才能得到(nms+b-box regression)bounding-box
三个模块(CNN特征提取、SVM分类和边框修正)是分别训练的,并且在训练的时候,对于存储空间的消耗大。检测速度慢,47s/per image。
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPP-net)ECCV 2014 何恺明
核心贡献:在R-CNN的基础上提出了空间金字塔变换层,速度、精度提升。
【CNN网络后面接的FC层需要固定的输入大小:FC层在设计时就固定了神经元的个数,故需要固定长度的输入限制网络的输入大小
CNN网络会有大量的重复计算,造成的计算冗余】
R-CNN:输入需要对候选区域做填充到固定大小【对候选区域做填充缩放操作,可能会让几何失真、有冗余信息,这都会造成识别精度损失】;每个候选区域都要塞到CNN内提取特征向量【一张图片有2000个候选区域,也就是一张图片需要经过2000次CNN的前向传播,这2000重复计算过程会有大量的计算冗余,耗费大量的时间。】
SPP-net:针对候选框的重复计算部分,候选区域到全图的特征映射之间的对应关系。【直接获取到候选区域的特征向量,不需要重复使用CNN提取特征】
使用空间金字塔变换层将接收任意大小的图像输入,输出固定长度的输出向量。
【相当于从中间截断了,那前面的CNN可以接受不同尺寸图像了。都是为了保证全连接层的一个固定】
空间金字塔变换层
以不同的大小的bin块来提取特征的过程。【成列向量与下一层全链接层相连。这样就消除了输入尺度不一致的影响。】
不同大小侯选区域在feature map上的映射塞给SPP层
SPP layer分成1x1(塔底),2x2(塔中),4x4(塔顶)三张子图,对每个子图的每个区域作max pooling。输出都是(16+4+1) 每个块提取出一个特征21维特征向量。然后×256。【其实就是从这21个图片块中,分别计算每个块的最大值,从而得到一个输出神经元】
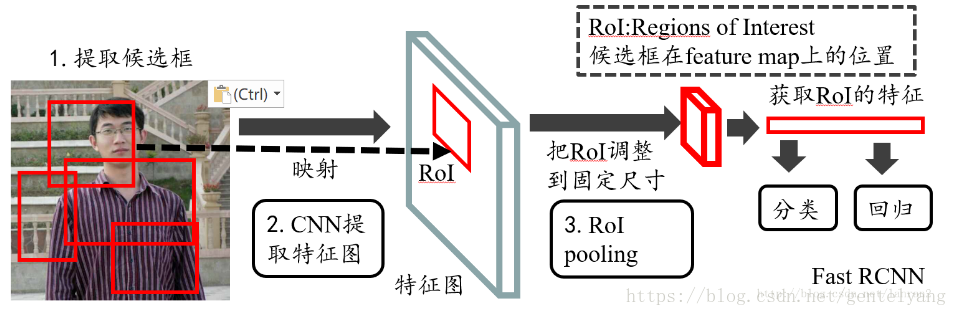
Fast R-CNN(CVPR 2015)
创新点:
SSP→RoI池化层:避免对每个候选区域提取特征,避免大量重复计算。
将分类与定位两大任务融入一个网络中来,获得了比R-CNN快的训练测试速度。边框回归直接加入到CNN网络中训练,损失部分采用多任务损失:
方法:
利用选择性搜索获取图像中的推荐区域→将原始图片利用VGG16网络进行提取特征,之后把图像尺寸、推荐区域位置信息和特区得到的特征图送入RoI池化层,进而获取每个推荐区域对应的特征图。
input:待处理的整张图像;候选区域
网络分成两个并行分支,一个对推荐区域进行分类,一个对推荐区域的位置信息做预测。
RoI池化层:
【对SSP改进部分,SSP有不同尺度的特征图。这边简化了一下下采样到统一尺度】RoI只采用单一尺度进行池化→VGG16 后产生一个7×7×512维度的特征向量作为全连接层的输入【每个RoI区域的卷积特征分成4×4个bin,然后对每个bin内采用max pooling,这样就得到一共16维的特征向量。】
RoI pooling解决了SPP无法进行权值更新的问题。【?解答:SPP是将所有的特征图上的RoI保存下来,然后选择进行的网络微调,不会更新SSP layer之前的层,就相当于和前面的断开了,前面的特征图都不共享。Fast就是从输入到选择RoI都是同一批图,这样就能效率高的反向传播了。】
两个好处:将图像中的RoI区域定位到卷积特征中的对应位置;将这个对应后的卷积特征区域通过池化操作固定到特定长度的特征,然后将该特征送入全连接层
采用SVD对全连接层分解:
一张图像约产生2000个RoI,近一半的前向传递时间都花在计算全连接层上。SVD对全连接层进行变换来提高运算速度。截断SVD可以减少30%以上的检测时间,mAP只下降很小(0.3个百分点)。
一个大的矩阵可以近似分解为三个小矩阵的乘积,分解后的矩阵的元素数目远小于原始矩阵的元素数目,从而达到减少计算量的目的。→对全连接层的权值矩阵进行SVD分解。
多任务的损失
Fast R-CNN直接使用Softmax替代SVM分类,利用Softmax Loss 和Smooth L1 Loss对分类概率和边框回归联合训练
【Fast R-CNN网络主要有2个网络分支,一个网络分支负责输出推荐区域的分类概率,另一个网络分支负责输出每个推荐区域位置信息偏移量。】
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
RCNN FastRCNN总结对比
二者的ROI区域生成:单独模块 选择性搜索
RCNN把分类和坐标分成两个网络,fastRCNN加上特征提取融合在一起了(Deepnet)。
创新点:
使用RPN生成检测框,提高检测框生成速度。区域生成网络(RPN)+Fast RCNN
产生建议窗口的CNN和目标检测的CNN共享
核心方法:
使用卷积层提取特征图:
conv x13 relux13 poolingx4
conv层:kernel_size=3,pad=1,stride=1
对卷积进行填充:【相当于保持尺度不变 假设输入MxN 进来后(M+2)x(N+2) 那么3x3输出后还是MxN】
pooling层:kernel_size=2,pad=0,stride=2
【假设输入MxN 进来后(M+2)x(N+2) 那么2x2步长2输出后(M/2)x(N/2)→四次pool就变成了1/16 特征图上面密集的点对应到原始图像上面有16个像素的间隔】 最后conv5输出通道数有256(针对ZF :VGG16是512-d,ZF是256-d)
【800/16 x 600/16=50 x 38 特征一共是50 x 38 x 256】
RPN网络生成检测框:【相当于目标定位,二分类】
input: (M/16)x(N/16) 先经过一次3x3卷积 output: 50 x 38 x 256
分成两条线:
softmax判断正负样例
bb回归修正→proposals精准化
每一个点都负责原图中对应位置的9种尺寸框的检测→50 x 38 x 9 个anchor
【anchors多尺度方法:9个尺度,三种形状→长宽比1:1 1:2 2:1】
【可理解为在原图尺度上,设置了许多候选Anchor。通过CNN判断标记有目标的positive anchor和没目标的negative anchor】
正负样本怎么划分:
1 对每个标定的ground truth区域,与其重叠比例最大的anchor记为正样本。【一个gt对应一个正样本】
2 剩余的anchor,如果其与某个标定区域重叠比例大于0.7,记为正样本【每个ground truth可能会对应多个正样本anchor。但每个正样本anchor 只可能对应一个grand truth 一对多关系】。
如果其与任意一个标定的重叠比例都小于0.3,记为负样本。
3 剩余的anchor、跨越图像边界的anchor丢弃
计算anchor box与ground truth之间的偏移量:ground truth box与预测的anchor box之间的差异
损失:rpn_loss_cls【softmax】、rpn_loss_bbox【smooth L1】、rpn_cls_prob【用于下一层的nms非最大值抑制操作】
p表示anchor i预测为物体的概率
p×正样本=1负样本=0 【回归只有在正样本时候才会被使用!】
t表示正样本anchor到预测区域的4个平移缩放参数
t×正样本anchor到Ground Truth的4个平移缩放参数
生成anchors →softmax分类器提取positvie anchors →bbox回归positive anchors →Proposal Layer生成proposals
Roi Pooling:【共享信息】
input:
特征图和proposals 提取proposal feature maps→后续全连接层判定目标类别
候选框的特征图水平和垂直分为7份,对每一份进行最大池化处理。49维送入全连接层。【即使大小不一样的候选区,输出大小都一样,实现了固定长度的输出】
分类:
利用已经获得的proposal feature maps,通过全连接层与softmax计算每个proposal具体属于的类别,输出cls_prob概率向量;再次利用bounding box regression获得每个proposal的位置偏移量bbox_预测,用于回归更加精确的目标检测框。
训练部分:
1 使用ImageNet模型初始化,独立训练一个RPN网络。
2 使用上面RPN网络产生的proposal作为输入,训练一个Fast-RCNN网络。【两个网络每一层的参数完全不共享】
3 使用上面的Fast-RCNN网络参数初始化一个新的RPN网络,但是把RPN、Fast-RCNN共享的那些卷积层的学习率设置为0,仅仅更新RPN特有的那些网络层,重新训练。两个网络已经共享了所有公共的卷积层
4 仍然固定共享的那些网络层,把Fast-RCNN特有的网络层也加入进来,形成一个network,继续训练,微调 Fast-RCNN特有的网络层实现网络内部预测proposal并实现检测的功能。