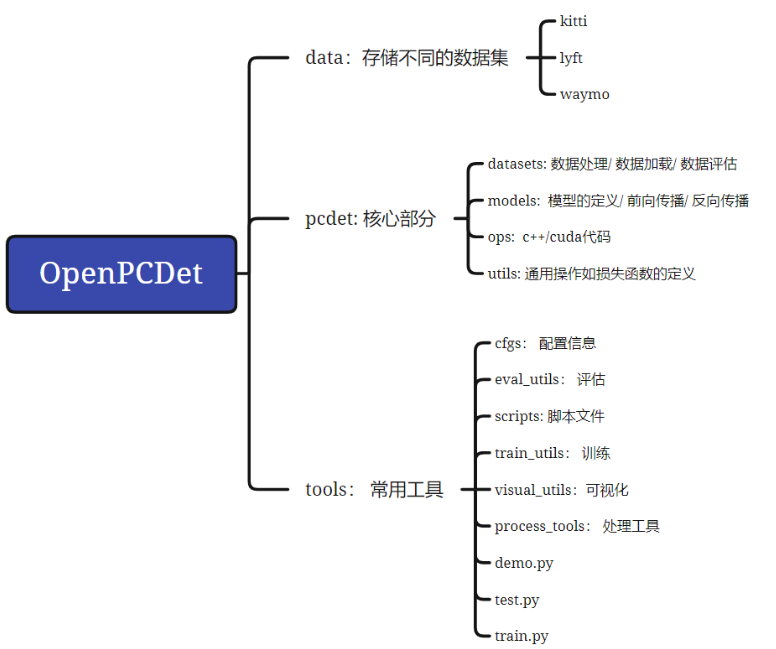
OpenPCDet
在PCDet中搭建3D目标检测框架只需要写config文件将所需模块定义清楚,然后PCDet将自动根据模块间的拓扑顺序组合为3D目标检测框架,来进行训练和测试
数据处理流程
Dataset Preparation 以KITTI数据集为例:
更改数据集配置文件: tools/cfgs/dataset_configs/kitti_dataset.yaml
生成the data infos:
1 | python -m pcdet.datasets.kitti.kitti_dataset create_kitti_infos tools/cfgs/dataset_configs/kitti_dataset.yaml |
Pretrained Models
Training & Testing
使用预训练模型测试和使用多GPUs测试
要测试特定训练设置的所有已保存检查点并在 Tensorboard 上绘制性能曲线,请添加参数:
--eval_all1
python test.py --cfg_file ${CONFIG_FILE} --batch_size ${BATCH_SIZE} --eval_all
要使用多个 GPU 进行测试,要执行以下操作:
1 | sh scripts/dist_test.sh ${NUM_GPUS} \ |
使用多GPUs训练
1 | sh scripts/dist_train.sh ${NUM_GPUS} --cfg_file ${CONFIG_FILE} |
以VOD数据集为例子PP-Radar复现
按照openPCDet框架中数据集中Kitti的格式,生成XXXXinfo.pkl 文件
需要更改两个cfg文件:一个是数据集的cfg文件,一个是模型的cfg文件【采用的是PointPillar Config】。
在PillarVFE需要进行更改:原因是因为在点云中没有RCS和Doppler特征。
在tensorboard进行查看:
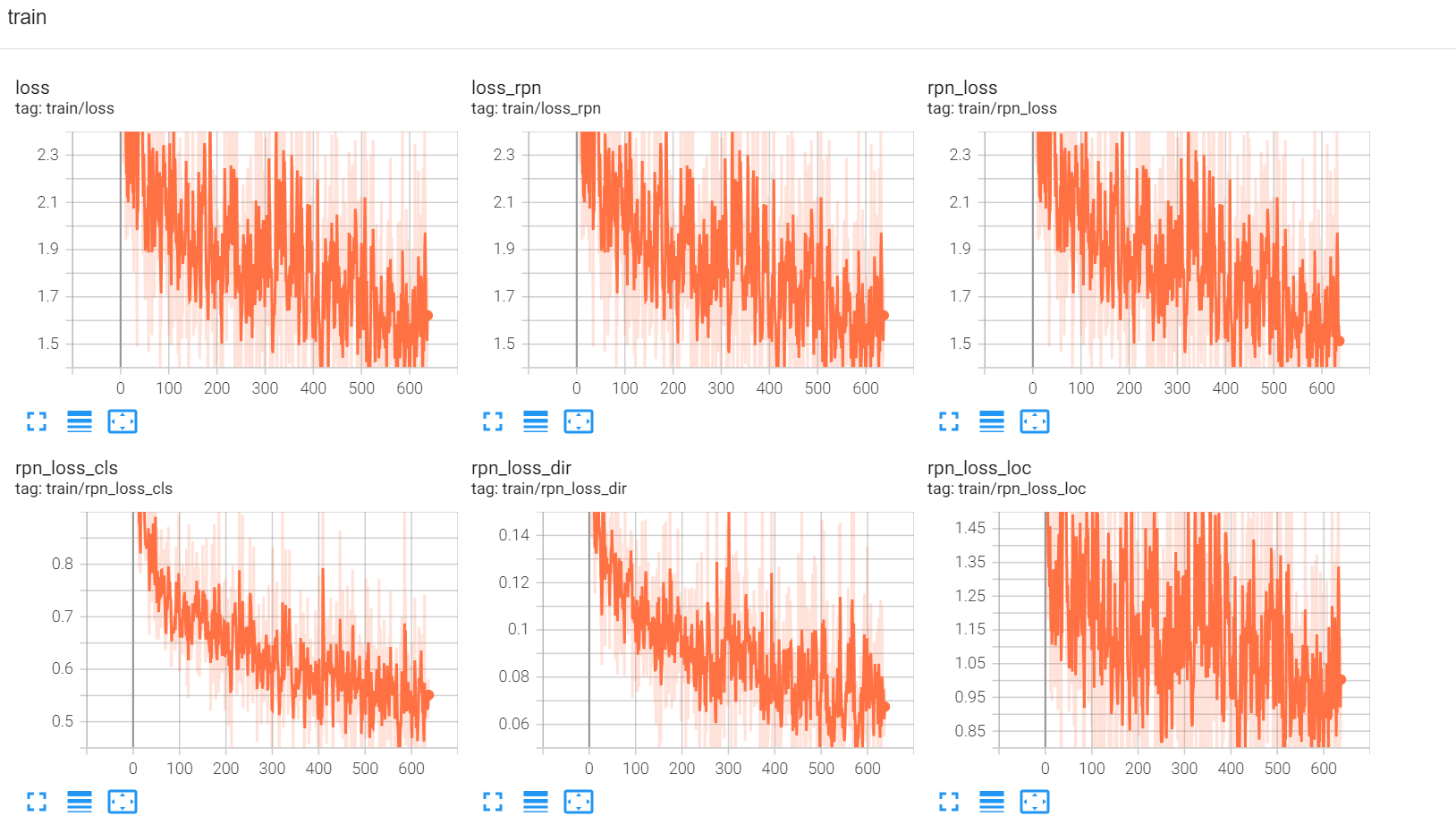
结果:

需要注意的是evaluate方法的修改~
MMDet3D
work flow
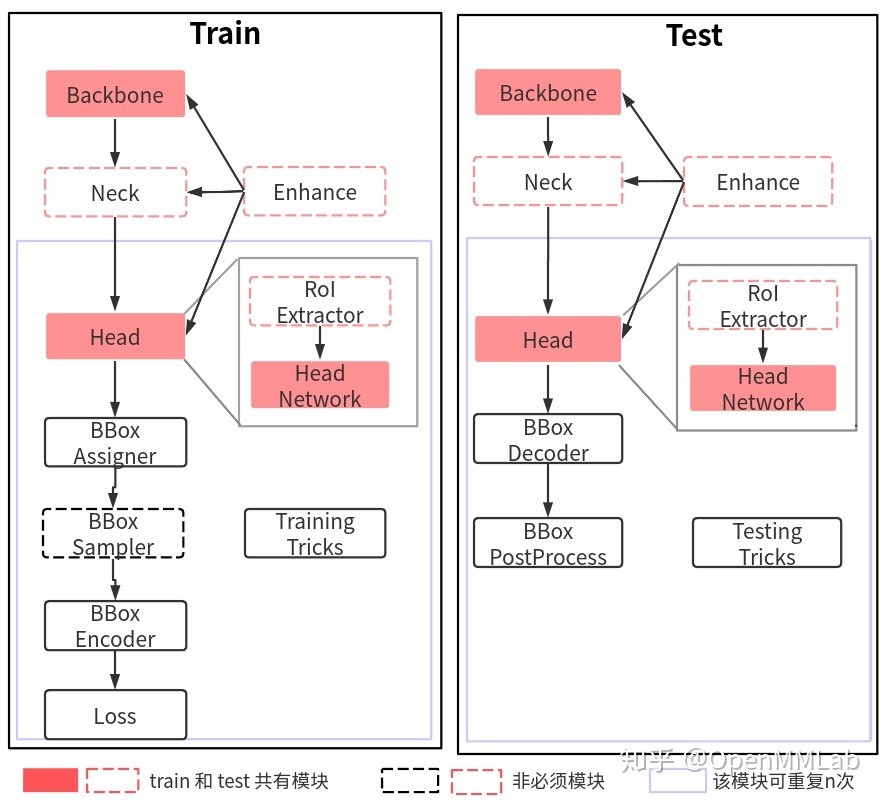
train
stream: batch → backbone → neck → head [cls + reg]→ gt bbox encoder→ loss
backbone
路径:mmdetection3d/mmdet3d/models/backbones
对backbone进行扩展,可以继承上述网络,然后通过注册器机制注册使用。通过 MMCV 中的注册器机制,你可以通过 dict 形式的配置来实例化任何已经注册的类
LEARN ABOUT CONFIGS
路径:mmdetection3d/configs/_base_
把这个路径下每个文件夹的内容选取组件进行组合,一共有4个组件:数据集 (dataset),模型 (model),训练策略 (schedule:Optimization config) 和运行时的默认设置 (default runtime:Hook config)
configs文件的命名风格:
1 | {model}_[model setting]_{backbone}_{neck}_[norm setting]_[misc]_[gpu x batch_per_gpu]_{schedule}_{dataset} |
DATASET PREPARATION
离线转换的方法将其转换为 KITTI数据集的格式,因此只需要在转换后修改配置文件中的数据标注文件的路径和标注数据所包含类别;对于那些与现有数据格式相似的新数据集,如 Lyft 数据集和 nuScenes 数据集,我们建议直接调用数据转换器和现有的数据集类别信息,在这个过程中,可以考虑通过继承的方式来减少实施数据转换的负担。
当现有数据集与新数据集存在差异时,可以通过定义一个从现有数据集类继承而来的新数据集类来处理具体的差异;最后,用户需要进一步修改配置文件来调用新的数据集。【waymo例子】
路径:mmdetection3d/mmdet3d/datasets
自定义数据集:将标注信息重新组织成一个 pickle 文件格式的字典列表 标注框的标注信息会被存储在 annotation.pkl 文件中 在 mmdet3d/datasets/my_dataset.py 中创建一个新的数据集类来进行数据的加载。
统合数据集或者修改数据集的分布,并应用到模型的训练中。
RepeatDataset:简单地重复整个数据集ClassBalancedDataset:以类别平衡的方式重复数据集ConcatDataset:拼接多个数据集
CUSTOMIZE DATA PIPELINES
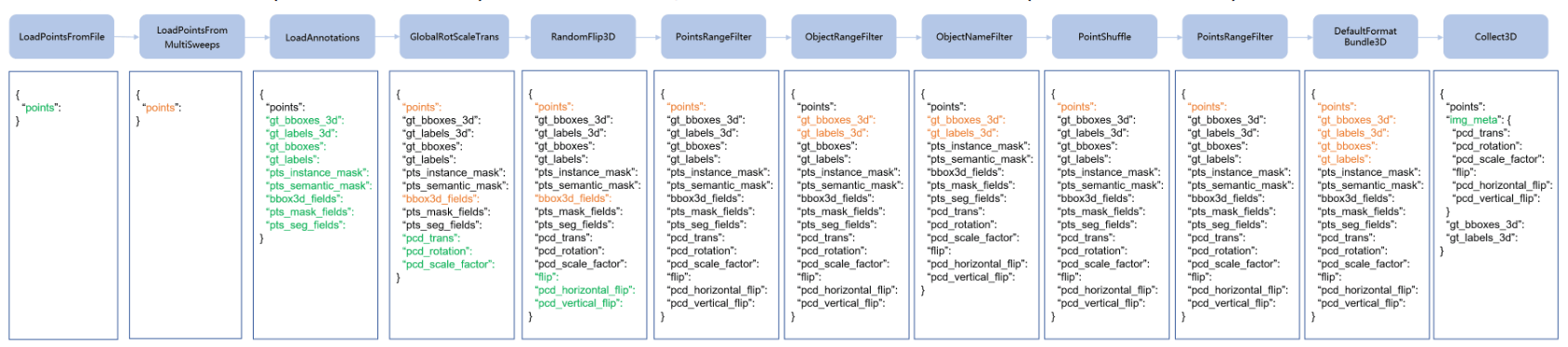
数据加载、预处理、格式化、测试时的数据增强
CUSTOMIZE Model
通常把模型的各个组成成分分成6种类型:
- 编码器(encoder):包括 voxel layer、voxel encoder 和 middle encoder 等进入 backbone 前所使用的基于 voxel 的方法,如 HardVFE 和 PointPillarsScatter。
- 骨干网络(backbone):通常采用 FCN 网络来提取特征图,如 ResNet 和 SECOND。
- 颈部网络(neck):位于 backbones 和 heads 之间的组成模块,如 FPN 和 SECONDFPN。
- 检测头(head):用于特定任务的组成模块,如检测框的预测和掩码的预测。
- RoI 提取器(RoI extractor):用于从特征图中提取 RoI 特征的组成模块,如 H3DRoIHead 和 PartAggregationROIHead。
- 损失函数(loss):heads 中用于计算损失函数的组成模块,如 FocalLoss、L1Loss 和 GHMLoss。
针对每个组成成分进行添加和修改。